Future of the NIDA Center of Excellence in Omics, Systems Genetics, and the Addictome
The future of the OSGA Center …
We were fortunate to have funding to initiate the NIDA Center of Excellence in Omics, Systems Genetics, and the Addictome from 2017 through 2023. We are back at it, trying to secure funding to REVIVE the OSGA Center. We have reorganized and turned our focus to building community. Our leadership team returns (Dr. Laura Saba, Dr. Rob Williams, and Dr. Saunak Sen) with the addition of Dr. Hao Chen from the University of Tennessee Health Science Center.
The goal of the NIDA Core Center of Excellence in Omics, Systems Genetics, and the Addictome (OSGA Center) is to build and empower a community of SUD researchers who will capitalize on big data approaches to establish causal linkages between molecular and cellular traits with risk of substance use and misuse, risk of relapse, and treatment efficacy.
We believe that to enable the wide-spread use of data science/quantitative genetics/artificial intelligence techniques—those that will make the goal of precision medicine solutions for SUD treatment and prevention attainable—both the next generation and the current generation of addiction scientists NEED (1) high-quality training in quantitative skills, (2) big data resources, and (3) big data tools to enhance current research projects.
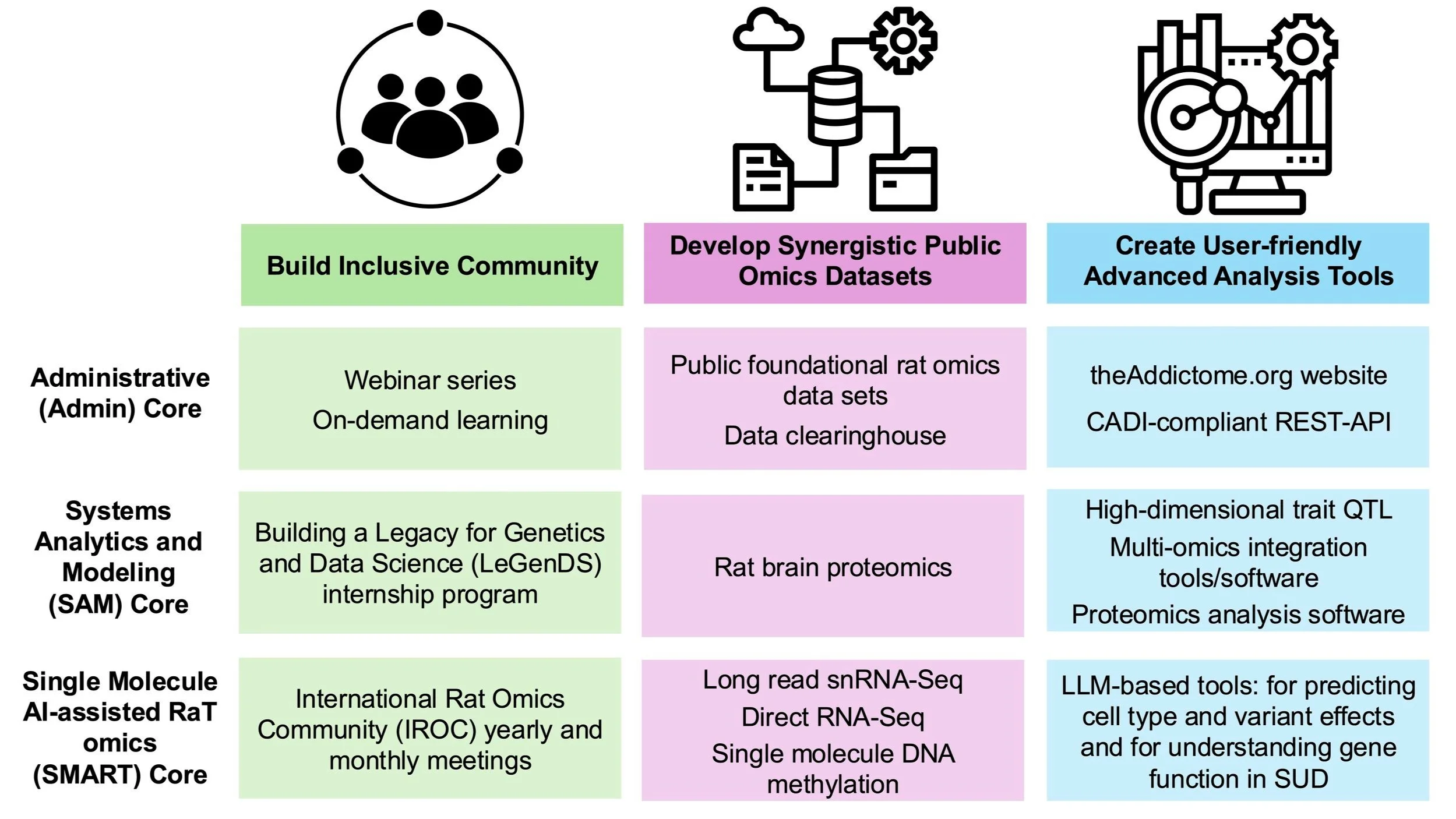
Aim 1 - Community: Stimulate the use of omics, systems genetics, and advanced computational and statistical modeling in SUD research by training current SUD researchers, by recruiting future SUD researchers, and by building communities around these core areas of research. We previously ran a highly successful webinar series that featured talks on all facets critical to our mission. This series will be restarted, and ‘popular’ webinars will be revamped with hands-on exercises. We will introduce dynamic workbooks to jump-start a better way of scientific data analysis, curation, sharing, and communication. We will recruit researchers to the field through our pilot grant program and our Building LeGenDS (Legacy for Genetics and Data Science) program. The LeGenDs program has been designed to promote diversity within SUD genetics and data science communities through undergraduate and graduate research experiences. We will continue to foster collaborations and interactions among rat omics researchers using the yearly meeting of the International Rat Omics Community (IROC), the biennial Addiction Genetics and Epigenetics Data Jamboree, and our pilot grant program.
Aim 2 - Data: Expand and optimize foundational omics rat datasets that can be used by all to enhance funded NIDA research and to enable advanced systems analyses. The lofty goal of precision medicine solutions to SUD starts with big data. We and others have generated key genome, transcriptome, and proteome data sets for two widely used and genetically diverse rat populations—the NIH Heterogeneous Stock (HS) and the Hybrid Rat Diversity Panel (HRDP). These large well-curated data sets already allow SUD researchers to explore how big data can accelerate research on day-one of their research projects and provide a complementary open resource to combine with their own data for further insight into functional hypotheses. We will strategically add to these data sets (proteomics, single nuclei transcriptomics, RNA modifications, and DNA methylation) to include information on cell-type specific processes and post-transcription processes that may not be captured in a single R01 experiment but have the potential for significant functional impact.
Aim 3 - Tools: Provide cutting-edge statistical and computational tools for the latest omics technologies, for multi-omic integration, for modeling of SUD, and for curating and accessing data. As technologies advance rapidly and as output from individual experiments grows almost exponentially, new computational and statistical tools are more than essential. The OSGA Center will continue to evaluate and devise new methods to improve the accuracy, relevance, and throughput of both the analysis of data and their use in powerful causal models of SUD and integration with AI-driven systems. With our passion for FAIR principles, we will also be working on the infrastructure needed to curate and share data and models efficiently and effectively.